
”Spark 集群计算“ 的搜索结果

实时计算框架:Spark集群搭建与入门案例。50字50字50字50字50字50字
在这篇文章中,我将提到介绍Spark的第一篇论文, Spark:具有工作集的集群计算 。 这篇文章将是有关我的GSoC项目的基础文章之一。 您可以从此处阅读有关我接受的建议的文章: GSoC 2015 Apache GORA的接受 。 ...
集群情况: 23台8核 32G内存服务器(主节点1台) 数据量:从spark中700W行数据中检索100W行数据 就是简单的SUM计算 ,计算时间约为3秒 请问这个速度是否正常,多谢!

下面来一起看看使用docker快速搭建Spark集群的方法教程。 适用人群 正在使用spark的开发者 正在学习docker或者spark的开发者 准备工作 安装docker (可选)下载java和spark with hadoop Spark集群 Spark运行时架构...
Local 模式: 在本地模式下,Spark 将作为一个单独的 Java 进程在本地运行,不...在 Standalone 模式下,Spark 自身作为一个独立的集群运行,可以通过启动 Spark Master 和 Spark Worker 进程来启动一个完整的 Spark 集
在上一篇文章《Hadoop集群搭建配置教程》中详细介绍了Hadoop集群搭建的全部过程,今天为大家带来分布式计算引擎Spark集群搭建,还是使用三个虚拟机节点上进行安装部署,围绕Standalone模式和Yarn模式的这两种部署...

Linux安装Spark集群 Spark可以在只安装了JDK、scala的机器上直接单机安装,但是这样的话只能使用单机模式运行不涉及分布式运算和分布式存储的代码,例如可以单机安装Spark,单机运行计算圆周率的Spark程序。...
本文章主要阐述在Standalone模式下,Spark集群的安装和配置。Yarn模式不需要启动spark集群,只需要启动hadoop集群即可,在启动hadoop集群之前,需要在yarn-site.xml文件关闭内存检查,否则在测试官方案例时可能会...
2. Spark 集群搭建 目标 从 Spark 的集群架构开始, 理解分布式环境, 以及 Spark 的运行原理 理解 Spark 的集群搭建, 包括高可用的搭建方式 2.1. Spark 集群结构 目标 通过应用运行流程, 理解分布式...
本文是Spark调研笔记的最后一篇,以代码实例说明如何借助Spark平台高效地实现推荐系统CF算法中的物品相似度计算。 在推荐系统中,最经典的推荐算法无疑是协同过滤(Collaborative Filtering, CF),而item-cf又是CF...


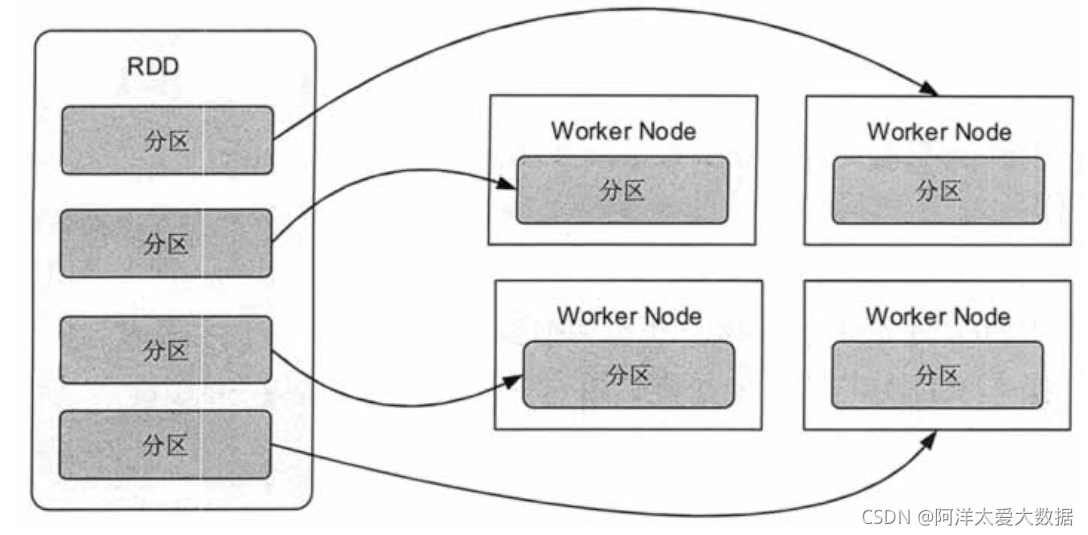
Spark集群模式&Spark程序提交1. 集群管理器Spark当前支持三种集群管理方式Standalone—Spark自带的一种集群管理方式,易于构建集群。Apache Mesos—通用的集群管理,可以在其上运行Hadoop MapReduce和一些服务...

Spark集群安装
IDEA连接spark集群写在前面一、安装Scala插件二、新建一个Maven项目三、编写pom.xml文件四、导入Scala环境五、编写Scala程序并提交给集群 写在前面 我所使用的spark集群是基于docker搭建的,一共三个节点,一个...
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架。可以通过Python构建Spark任务。
Apache Spark(后续简称为Spark)是一款正在点燃大数据世界的开源集群计算框架。据Spark Certified Experts显示,在内存中运行时,Sparks性能要比Hadoop快一百倍,在磁盘上运行,Sparks比Hadoop快达十倍。在本篇博客中...



Spark-在工作集上进行集群计算是scala作者Matei Zaharia发表的论文,这是它的中文翻译版本。

在集群上运行spark程序时,rdd的操作都在worker机上,因此输出rdd的元素将在worker机的标准输出上进行,驱动节点上不会运行,故直接才程序中写如下代码 rdd.foreach(println(_)) 并不能产生期望的结果。此时应该先...
推荐文章
- Unity3D 导入资源_unity怎么导入压缩包-程序员宅基地
- jqgrid 服务器端验证,javascript – jqgrid服务器端错误消息/验证处理-程序员宅基地
- 白山头讲PV: 用calibre进行layout之间的比对-程序员宅基地
- java exit方法_Java:如何测试调用System.exit()的方法?-程序员宅基地
- 如何在金山云上部署高可用Oracle数据库服务_rman target sys/holyp#ssw0rd2024@gdcamspri auxilia-程序员宅基地
- Spring整合Activemq-程序员宅基地
- 语义分割入门的总结-程序员宅基地
- SpringBoot实践(三十五):JVM信息分析_怎样查看springboot项目的jvm状态-程序员宅基地
- 基于springboot+vue的戒毒所人员管理系统 毕业设计-附源码251514_戒毒所管理系统-程序员宅基地
- 【LeetCode】面试题57 - II. 和为s的连续正数序列_leet code 和为s的正数序列 java-程序员宅基地